La
normalización se adoptó porque el viejo estilo de poner todos los datos en un
solo lugar, como un archivo o una tabla de la base de datos, era ineficiente y
conducía a errores de lógica cuando se trataba de manipular los datos. Por
ejemplo, vea la base de datos MiTienda. Si almacena todos los datos en la tabla
Clientes, ésta podría verse como se muestra a continuación:
Clientes
- ID_Cliente Nombre
- Apellidos
- Nombre_Producto1
Costo_Producto1
- Imagen_Producto1
Nombre_Producto2 Costo_Producto2
- Imagen_Producto2
Fecha_Pedido
- Cantidad_Pedido
- Nombre_Cia_Envios
A
diferencia de los datos no normalizados, una tabla está en 1FN si y solo
si es "isomorfa a alguna relación", lo que significa,
específicamente, que satisface las siguientes cinco condiciones:
- No hay orden de
arriba-a-abajo en las filas.
- No hay orden de
izquierda-a-derecha en las columnas.
- No hay filas
duplicadas.
- Cada intersección de
fila-y-columna contiene exactamente un valor del dominio aplicable (y nada
más).
- Todas las columnas son
regulares [es decir, las filas no tienen componentes como IDs de fila, IDs
de objeto, o timestamps ocultos].
Ejemplo
: (No Normalizada)

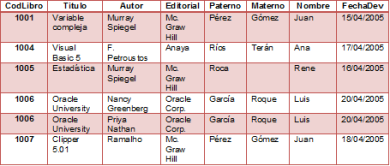
En esta
tabla podemos apreciar que los datos del lector no están atomizados
porque el nombre del lector se puede descomponer en Nombre, Apellidos (Paterno
y Materno).
En
cambio, en la siguiente tabla los datos del lector se encuentra ya atomizados,
pero sucede que los datos del lector no
tiene mayor incidencia con las del libro entonces sucede un tipo
de redundancia que es normal en la 1FN pero que en la 2FN se
optimiza.
Ejemplo:
Cliente (1FN)
|
ID
Cliente
|
Nombre
|
Apellido
|
|
123
|
Todd
|
Ingram
|
|
456
|
James
|
Wright
|
|
789
|
Cesar
|
Du
|
Teléfono del cliente (1FN)
|
ID
Cliente
|
Teléfono
|
|
123
|
555-861-2025
|
|
456
|
555-403-1659
|
|
456
|
555-776-4100
|
|
789
|
555-808-9633
|
No hay comentarios:
Publicar un comentario